Design Methods
Chapter 2 — Design principles, failure analysis, decision logic, and key dimensions
2.1 Executable Design Principles
Effective boundary security design is grounded in a set of executable principles that are directly traceable to compliance frameworks, threat models, and operational experience. Each principle below includes its basis and the specific context in which it should be applied, enabling design teams to make consistent, defensible decisions across all boundary types.
| # | Principle | Basis | Apply When |
|---|---|---|---|
| 1 | Default deny between trust zones | Zero Trust / audit control | Multiple business units share network infrastructure |
| 2 | Least privilege, identity-aware access | Compliance & least privilege | Admin, third-party, and sensitive application access |
| 3 | Separation of duties (SoD) for policy vs. operation | SOC 2 / ISO 27001 | Firewall rule approvals and change management |
| 4 | Defense-in-depth at exposure points | Threat model | All internet-facing services; combine router filters + NGFW + WAF + DDoS |
| 5 | Route and policy symmetry | Stateful inspection requirements | Wherever stateful firewalls exist; prevents session bypass |
| 6 | Immutable, versioned configurations | Change control | All boundary devices; use Git-like repo + signed releases |
| 7 | Logging as a first-class requirement | Audit / forensics | All deployments; define log schema, retention, completeness SLO |
| 8 | Fail-safe vs. fail-open explicitly decided per service | Business continuity planning | Critical auth paths → fail-closed; public info sites → may allow fail-open under DDoS |
| 9 | Capacity ceiling at 70% sustained utilization | Stability engineering | All enforcement devices; above 70%, latency spikes and failovers fail |
| 10 | Security controls are testable and measurable | Acceptance engineering | Every control maps to a measurable acceptance test |
| 11 | Cryptographic agility | Lifecycle management | All TLS/IPsec deployments; plan for cipher deprecation and certificate rotation |
| 12 | Minimize exposed management planes | Hardening | All boundary devices; OOB only, IP allowlist, MFA, bastion host |
2.2 Trust Zone Architecture & Segmentation
The segmentation model defines five trust zones arranged in concentric rings of decreasing trust. Each zone boundary is enforced by a dedicated firewall context or VRF routing policy that implements default-deny inter-zone rules. This architecture ensures that a compromise in any outer zone cannot automatically propagate to inner zones without traversing an enforcement point. The diagram below illustrates the complete zone model with allowed traffic flows and blocked paths.
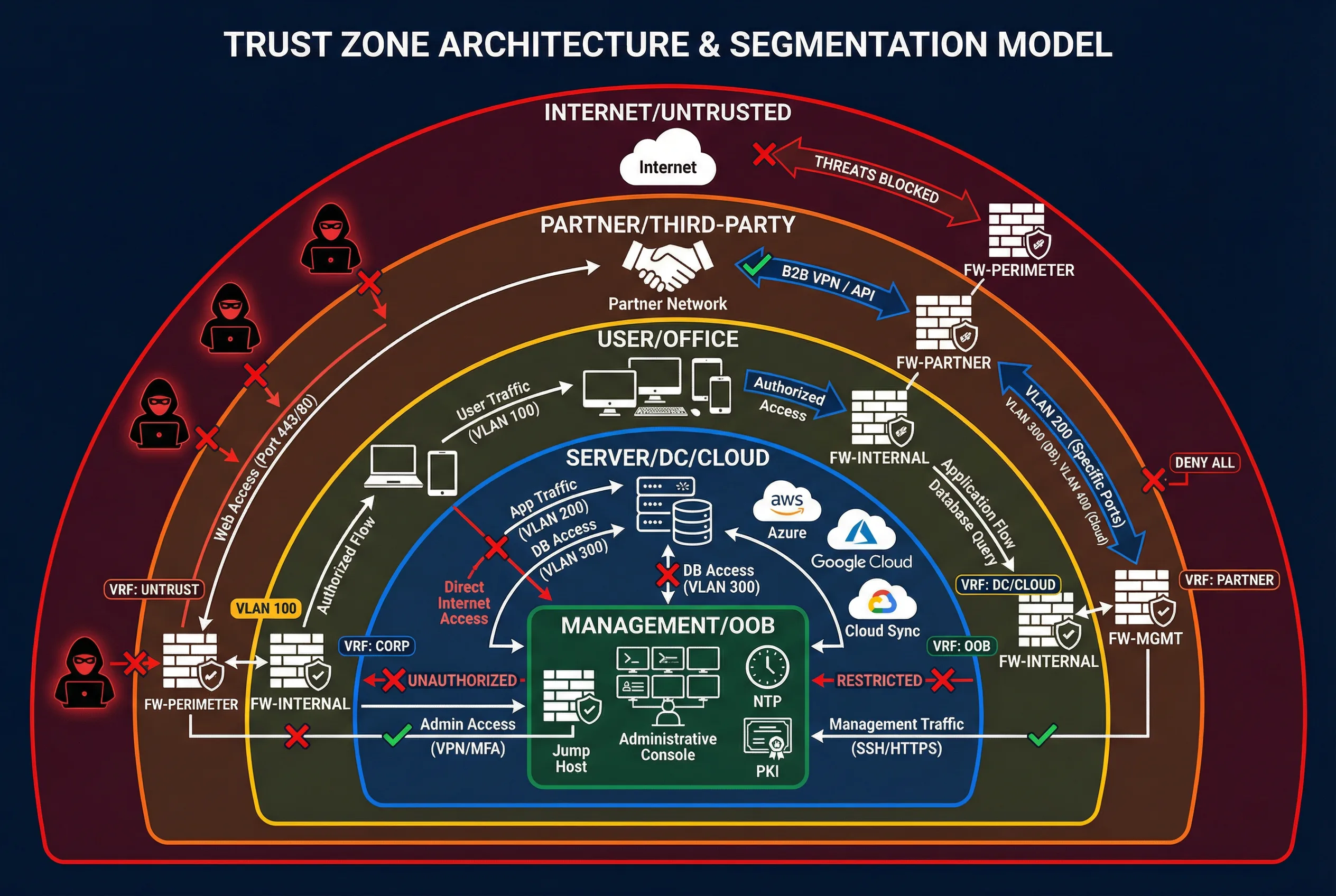
Figure 2.1: Trust Zone Architecture & Segmentation Model — Five trust zones with enforcement points, VRF/VLAN labels, and traffic flow policies
| Zone | Trust Level | Typical Occupants | Enforcement Mechanism | Default Inter-Zone Policy |
|---|---|---|---|---|
| Internet/Untrusted | Zero | Public internet, threat actors | Edge router ACL + NGFW outside interface | Deny all inbound; explicit allow for published services |
| Partner/Third-party | Low | B2B partners, vendor networks | Dedicated partner VRF + firewall context | Deny all; explicit allow per contract and protocol |
| User/Office | Medium | Workstations, laptops, mobile devices | NGFW inside interface + NAC (optional) | Allow outbound to approved services; deny server-to-user |
| Server/DC/Cloud | High | Application servers, databases, cloud workloads | NGFW + cloud SG/NACL + micro-segmentation | Deny all; explicit allow per application flow |
| Management/OOB | Highest | Jump hosts, NTP, PKI, config managers | Dedicated OOB network + MFA bastion | Deny all production traffic; admin access via MFA only |
2.3 Failure Causes and Recommendations
Security boundary failures typically arise from a predictable set of architectural and operational root causes. The following table maps common failure causes to their failure mechanisms, avoidance recommendations, and verification methods. Understanding these patterns enables proactive design choices that prevent the most common security incidents and operational outages.
| Common Failure Cause | Failure Mechanism | Avoidance Recommendation | Verification Method |
|---|---|---|---|
| Flat network architecture | Lateral movement is unrestricted | VRF/VLAN segmentation + inter-zone firewall | Path test + policy audit |
| Rule sprawl | Shadow allow rules remain indefinitely | Rule lifecycle with expiry dates + named owners | Quarterly rule review report |
| Asymmetric routing | Sessions drop or bypass stateful inspection | Enforce symmetry via PBR/ECMP controls | Traceroute in both directions |
| Unmanaged exposure | Unknown internet endpoints accumulate | EASM + CMDB + periodic exposure scans | Exposure inventory delta report |
| TLS blind spots | Attacks hidden within encrypted traffic | Selective TLS inspection + JA3/metadata analysis | TLS inspection coverage report |
| Log gaps | Missing detection and audit evidence | Source onboarding checklist + completeness SLO | Daily log health dashboard |
| HA not tested | Failover fails during actual incident | Quarterly failover drills with documented results | RTO/RPO evidence from drills |
| Third-party overtrust | Partner network becomes lateral movement pivot | ZTNA per-app access, JIT accounts, session recording | Access review records + session logs |
2.4 Core Design and Selection Logic
The boundary design decision process follows a structured sequence that begins with service and data inventory and proceeds through zone definition, enforcement point selection, capacity sizing, policy template creation, logging integration, and acceptance testing. This sequence ensures that design decisions are made in the correct order, with each step building on validated outputs from the previous step. The following decision sequence provides a repeatable framework applicable to all boundary scenarios.
- Inventory services and data sensitivity; classify zones and flows based on business criticality.
- Determine exposure surface: inbound applications, outbound SaaS, partner access, and admin access paths.
- Choose enforcement points: centralized vs. distributed; inline vs. out-of-band based on latency and scale requirements.
- Select controls: NGFW features, WAF/API gateway, DDoS protection, ZTNA, DNS security, and NDR sensors.
- Size capacity: throughput, TLS inspection TPS, CPS, concurrent sessions, and SIEM EPS budget.
- Define policy templates and exceptions with mandatory expiry dates and named owners.
- Integrate logs into SIEM; define SOAR playbooks with approval guardrails and rollback procedures.
- Validate with controlled tests and drills; finalize runbooks and escalation procedures.
2.5 Key Design Dimensions
Boundary security design must balance multiple competing dimensions. The following table summarizes the key dimensions, their primary considerations, and the design trade-offs involved. Explicitly documenting these trade-offs during the design phase prevents misaligned expectations and enables informed decisions when constraints arise during implementation.
| Dimension | Primary Considerations | Key Trade-offs | Design Guidance |
|---|---|---|---|
| Performance & Experience | Latency, TLS overhead, SaaS breakout | Security depth vs. user latency | Measure 95th percentile latency; set SLA before deployment |
| Stability & Reliability | HA, redundant paths, state sync, convergence | Cost of redundancy vs. downtime risk | Active/active preferred; test failover quarterly |
| Maintainability & Replaceability | Modular design, standard interfaces, config as code | Vendor lock-in vs. integration simplicity | Abstract policies into templates; minimize vendor-specific constructs |
| Compatibility & Extension | Multi-vendor, cloud-native + on-prem parity | Consistency vs. cloud-native optimization | Prefer standard APIs (REST, STIX/TAXII, syslog TLS) |
| LCC / TCO | License, compute, storage, staffing, training | CAPEX (appliances) vs. OPEX (FWaaS/cloud) | Include log storage and staffing in TCO model |
| Energy & Environment | Power draw, cooling, physical footprint | Performance density vs. energy efficiency | Plan power budget per rack; include in data center capacity |
| Compliance & Certification | Audit mapping, evidence generation | Control granularity vs. operational overhead | Map controls to ISO 27001/SOC 2/PCI DSS from day one |
2.6 Working Principles and Exception Handling
Understanding the normal operating sequence and exception handling procedures is essential for both design and operations teams. The startup sequence defines the correct order for bringing boundary components online, ensuring that enforcement is active before traffic is admitted. Exception handling procedures define how the system responds to three common abnormal conditions that can affect security posture and availability.
Startup Sequence
- Power/UPS stable → switches and routers boot → verify link redundancy (LACP/MLAG).
- NGFW HA pair boots → state sync established → health checks pass.
- WAF/API gateway certificates loaded → backend health checks pass.
- Logging pipeline online: log collector → SIEM ingestion verified via heartbeat events.
- Security policies loaded from "golden baseline" repository; last-known-good version recorded.